5 自动化设计的程序实现
本文实现了一个简单的参数自动设计工具sizer 15 。整个程序使用Python编写,使用了面向对象的设计方法。
5.1 使用示例
使用sizer的典型工作流是
设计师用自己顺手的电路原理图编辑器,如KiCAD、Cadence Virtuoso等,绘制出电路原理图
在需要设计的参数处留下占位符。比如如果需要设计晶体管的长度,就在原理图编辑器里指定晶体管长度为
{w1},在变量两边加大括号将原理图导出为SPICE网表。也可以在这一步手动打开SPICE网表,在需要设计的参数处留占位符
用
sizer.CircuitTemplate读入SPICE网表用Python语言自定义损失函数
指定变量的边界范围
从
sizer.optimizers中选择一种优化算法运行,等待结果
从第4步开始,一切工作都在Python中完成。作者没有设计图形界面的原因是,Python语言本身已经足够简单,且用代码定制优化需求灵活方便,并且大而全的软件设计模式不符合KISS原则。
以一个简单Miller补偿的二阶运算放大器为例,SPICE网表如下
*Sheet Name:/OPA_SR
V1 Vp GND dc 1.65 ac 0.5
V2 Vn GND dc 1.65 ac -0.5
C2 Vout GND 4e-12
C1 /3 Vout {cm}
M7 Vout /6 VDD VDD p_33 l={l7} w={w7}
M6 Vout /3 GND GND n_33 l={l6} w={w6}
M2 /3 vp /1 VDD p_33 l={l12} w={w12}
M1 /2 vn /1 VDD p_33 l={l12} w={w12}
M4 /3 /2 GND GND n_33 l={l34} w={w34}
M3 /2 /2 GND GND n_33 l={l34} w={w34}
M5 /1 /6 VDD VDD p_33 l={l5} w={w5}
V0 VDD GND 3.3
M8 /6 /6 VDD VDD p_33 l={l8} w={w8}
I1 /6 GND 10e-6
.end其中大括号括起来的变量都是指定的需要设计的参数。一共13个变量。因为M1和M2是输入差分对管、M3和M4是输入差分对的负载管,所以它们完全对称、尺寸分别相等。

简单Miller补偿的二阶运算放大器电路原理图。网表中的电流镜像源管M8和镜像源管下方的电流源I1未画出。
一个典型的仿真代码文件如下
import sizer
import numpy as np
with open("./demos/two-stage-amplifier/two-stage-amp.cir") as f:
circuitTemplate = sizer.CircuitTemplate(f.read(), rawSpice=".lib CMOS_035_Spice_Model.lib tt")
def unityGainFrequencyLoss(circuit):
try:
return np.maximum(0, (1e+7 - circuit.unityGainFrequency) / 1e+7)
except:
return 1
def gainLoss(circuit):
return np.maximum(0, (1e+3 - np.abs(circuit.gain)) / 1e+3)
def phaseMarginLoss(circuit):
try:
return np.maximum(0, (60 - circuit.phaseMargin) / 60)
except:
return 0
def loss(circuit):
losses = [phaseMarginLoss(circuit), gainLoss(circuit), unityGainFrequencyLoss(circuit)]
return np.sum(losses)
bounds = {
w: [0.5e-6, 100e-6] for w in ["w12", "w34", "w5", "w6", "w7", "w8"]
}
bounds.update({
l: [0.35e-6, 50e-6] for l in ["l12", "l34", "l5", "l6", "l7", "l8"]
})
bounds.update({
"cm": [1e-12, 10e-12]
})
optimizer = sizer.optimizers.ScipyMinimizeOptimizer(circuitTemplate, loss, bounds, earlyStopLoss=0)
circuit = optimizer.run()
print(circuit.netlist)其中
import sizer import numpy as np用于导入sizer库和Python的科学计算库numpy。
with open("./demos/two-stage-amplifier/two-stage-amp.cir") as f: circuitTemplate = sizer.CircuitTemplate(f.read(), rawSpice=".lib CMOS_035_Spice_Model.lib tt")读入SPICE网表,生成电路模板
sizer.CircuitTemplate对象。def unityGainFrequencyLoss(circuit): try: return np.maximum(0, (1e+7 - circuit.unityGainFrequency) / 1e+7) except: return 1 def gainLoss(circuit): return np.maximum(0, (1e+3 - np.abs(circuit.gain)) / 1e+3) def phaseMarginLoss(circuit): try: return np.maximum(0, (60 - circuit.phaseMargin) / 60) except: return 1定义了3个硬约束,分别是
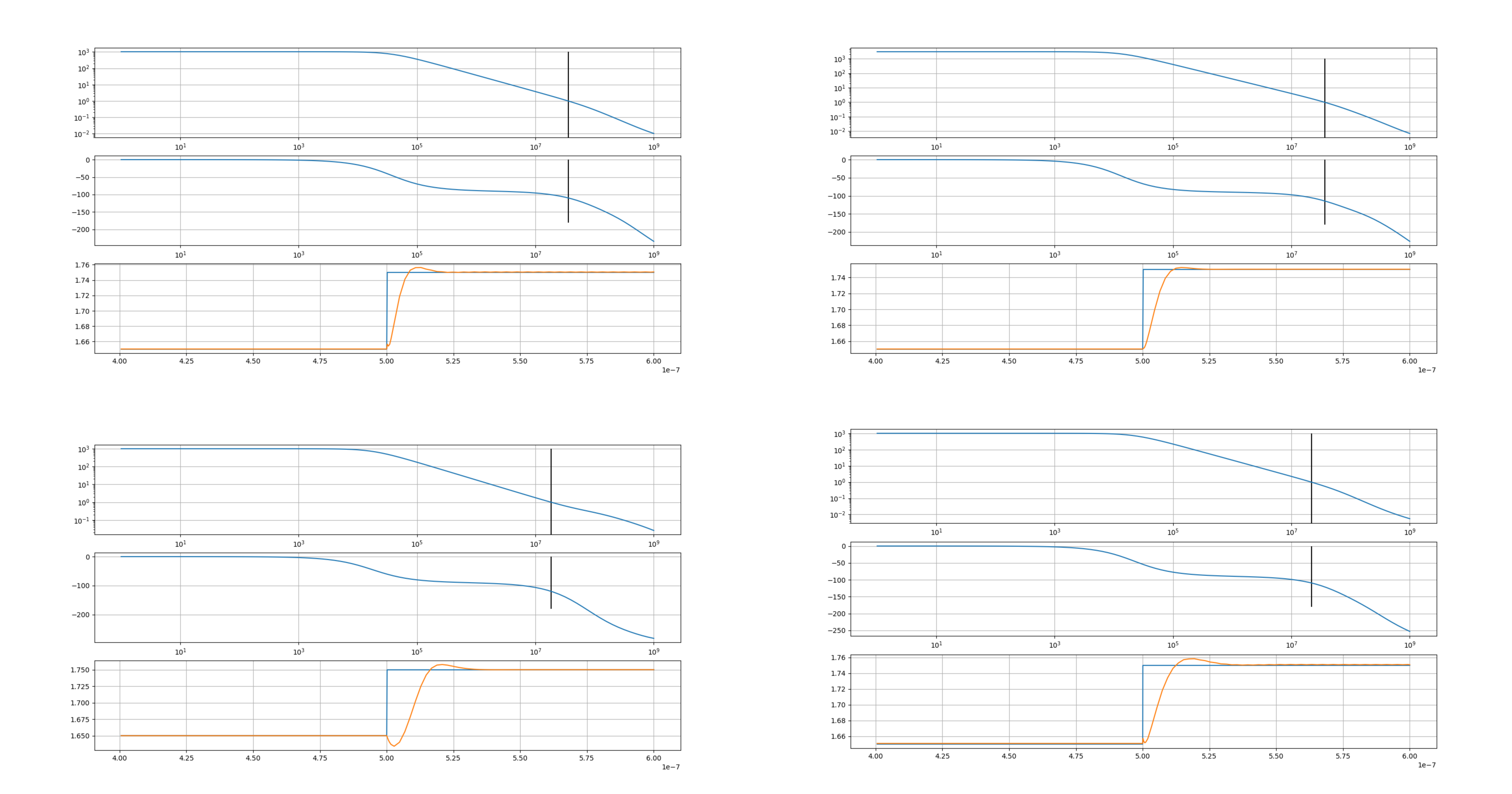
单位增益带宽不小于10 MHz
直流增益不小于1,000倍,即60 dB
相位裕度不小于60度
同时使用了ReLU损失函数形式,并且做了归一化处理。
单位增益、相位裕度的损失函数定义中含有处理异常的
try...except代码块的原因是,作者大量实验观察到,有时优化算法会生成一个根本不具有放大功能的异常电路,此时单位增益、相位裕度是无法定义的,所以直接令损失函数为1,这样可以告诉优化器设计师对这个电路很不满意,方便优化器做出下一步判断。def loss(circuit): losses = [phaseMarginLoss(circuit), gainLoss(circuit), unityGainFrequencyLoss(circuit)] return np.sum(losses)将三个损失函数加起来,形成了total loss。
bounds = { w: [0.5e-6, 100e-6] for w in ["w12", "w34", "w5", "w6", "w7", "w8"] } bounds.update({ l: [0.35e-6, 50e-6] for l in ["l12", "l34", "l5", "l6", "l7", "l8"] }) bounds.update({ "cm": [1e-12, 10e-12] })指定每个设计参数的边界范围。设定了每个晶体管的宽度在 \([0.5 \mu, 100 \mu]\) 之间,长度在 \([0.35 \mu, 50 \mu]\) 之间,补偿电容在 \([1 p, 10 p]\) 之间。
optimizer = sizer.optimizers.ScipyMinimizeOptimizer(circuitTemplate, loss, bounds, earlyStopLoss=0)指定目标函数优化算法是
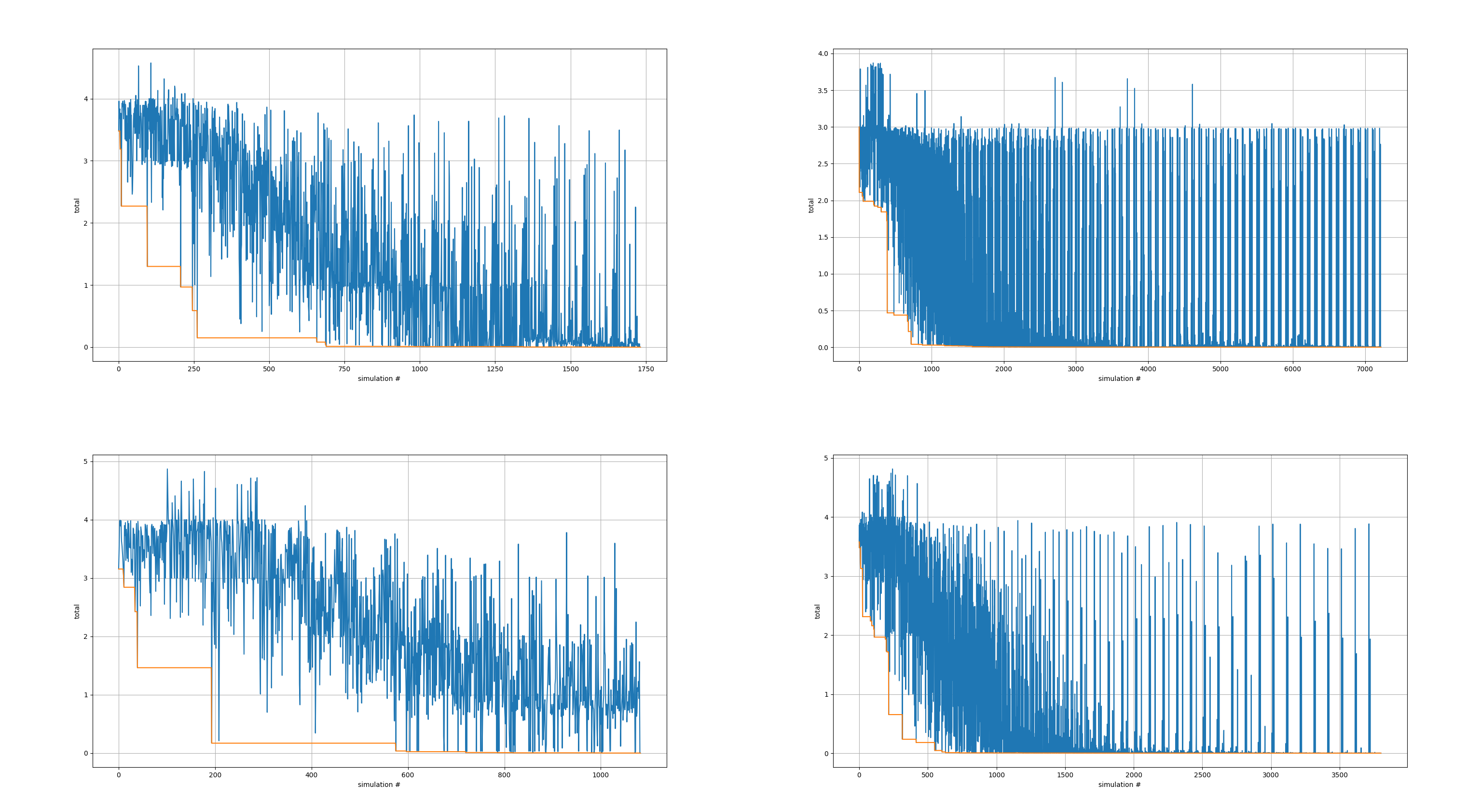
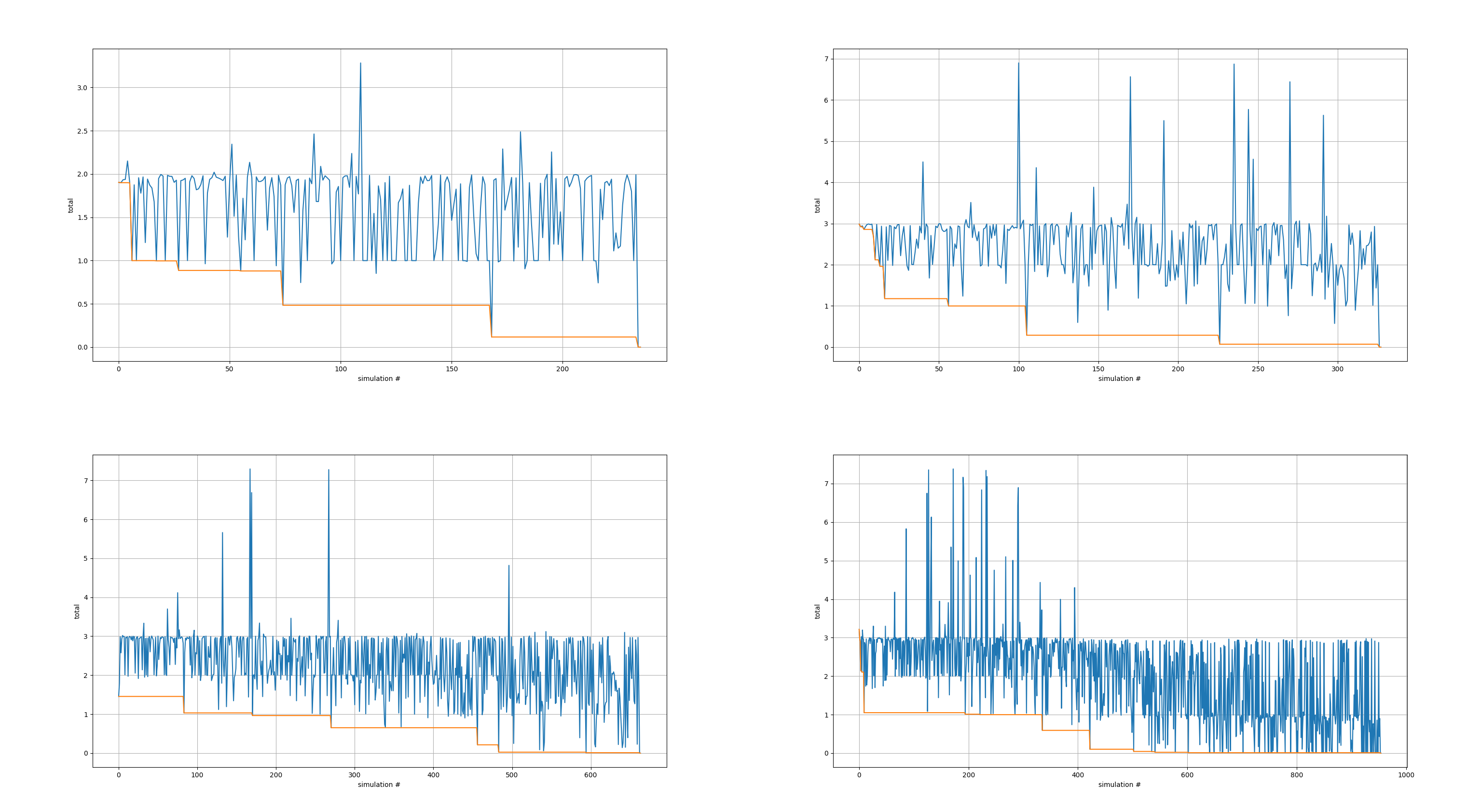
scipy实现的BFGS算法。指定电路模板、损失函数、变量边界,此外还指定了一旦遇到某个具体电路的total loss是0就立即停止优化,因为这个示例里,没有目标函数,只有三个硬性约束,只要达到就好,total loss为0即说明三个硬性约束已经全部同时满足,没有必要再继续优化下去了。circuit = optimizer.run() print(circuit.netlist)开始运行优化。优化结束后,
optimzer.run()才会返回表示最优电路的sizer.Circuit对象,然后第二行会打印出最优电路的SPICE网表。这个示例只需要大概20秒就可以出结果。
5.2 程序整体框架
程序包含三个模块
顶层模块
sizer包含三个重要的类
sizer.CircuitTemplate代表电路模板主要用来读取含有未定参数的电路的SPICE网表,并在优化算法调用自己时,生成具体电路
sizer.Circuit对象,传入用户自定义的损失函数里。sizer.Circuit代表具体电路表示一个不含有任何未确定参数的具体的、完全确定的电路,由
sizer.CircuitTemplate加上所有变量的定值之后实例化产生。提供了许多方便直接提取性能指标的帮助 getter 方法,例如sizer.Circuit.gain可直接得到这个具体电路的直流增益sizer.Circuit.bandwidth可直接得到带宽sizer.Circuit.phaseMargin可直接得到相位裕度sizer.Circuit.unityGainFrequency可直接得到单位增益带宽
这些 getter 方法内部的实现仍然是先做仿真、调用
sizer.calculators里面的计算器函数、从仿真波形中提取性能参数。但是将这些方法与sizer.Circuit对象绑定在一起,可以给用户定义损失函数提供很大的便利,例如用户在定义增益损失函数的时候,可以直接写def gainLoss(circuit): gain = circuit.gain # 可以一行就得到增益! return np.max(0, 1000 - gain) # 此处使用了ReLU,你也可以用别的而无需在损失函数手写冗长的AC仿真语句、再调用计算器函数提取性能参数。此外这些方法还会自动从SPICE网表中找到输入节点、输出节点。 16
- 16
支持 vin+, vin-, vi+, vi-, vp, vn, vin, vi 命名的、及其大小写无关的输入节点,也支持差分输入;支持 vout, vo 命名的、及其大小写无关的输出节点。
sizer.CircuitTemplateList代表多个电路模板的集合通常,评价一个电路需要频域、直流、瞬态等多方面性能指标,为了得到这些性能指标,需要对一个核心电路加不同的外围电路,再做AC、DC、TRAN等各种仿真,最后再算出综合损失函数。
比如在设计运算放大器的时候,为了得到增益、相位裕度等频域指标,需要把放大器接成开环、加输入直流偏置,然后做AC仿真,但为了得到转换速率等瞬态指标,需要把放大器接成单位增益反馈形式,然后做TRAN仿真。显然这么多操作不可能用一个SPICE网表就能实现,需要多个网表同时替换样本参数向量,再各自做不同的仿真,从多个仿真结果中提取性能指标。
优化器
sizer.optimizers包含许多优化算法,可以在运行搜索前指定用哪个算法。常用的有
sizer.optimizers.ScipyDifferentialEvolutionOptimizer是scipy实现的differential evolution优化算法sizer.optimizers.ScipyMinimizeOptimizer是scipy实现的L-BFGS算法sizer.optimizers.PyswarmParticleSwarmOptimizer是pyswarm库实现的particle swarm算法
计算器
sizer.calculators包含从仿真结果波形中提取性能指标的计算函数。类似Cadence的calculators工具,输入一个波形,从波形中测量出性能指标(比如从频率响应波形中测量出PM)。常用的有
sizer.calculators.gain()从频率响应波形中提取直流增益sizer.calculators.bandwidth()从频率响应波形中提取3 dB带宽sizer.calculators.phaseMargin()从频率响应波形中提取相位裕度sizer.calculators.unityGainFrequency()从频率响应波形中提取单位增益频率(增益降到1的时候的频率)sizer.calculators.slewRate()从瞬态波形中提取切换速率sizer.calculators.risingTime()从瞬态波形中提取上升时间sizer.calculators.fallingTime()从瞬态波形中提取下降时间
基本上覆盖了常用的功能。但实际上,由于
sizer.Circuit里已经预先定义好了很多帮助参数,如sizer.Circuit.gain,可以直接得到增益,通常情况下没有必要手动提取出波形再用计算器分析。
5.3 性能参数提取
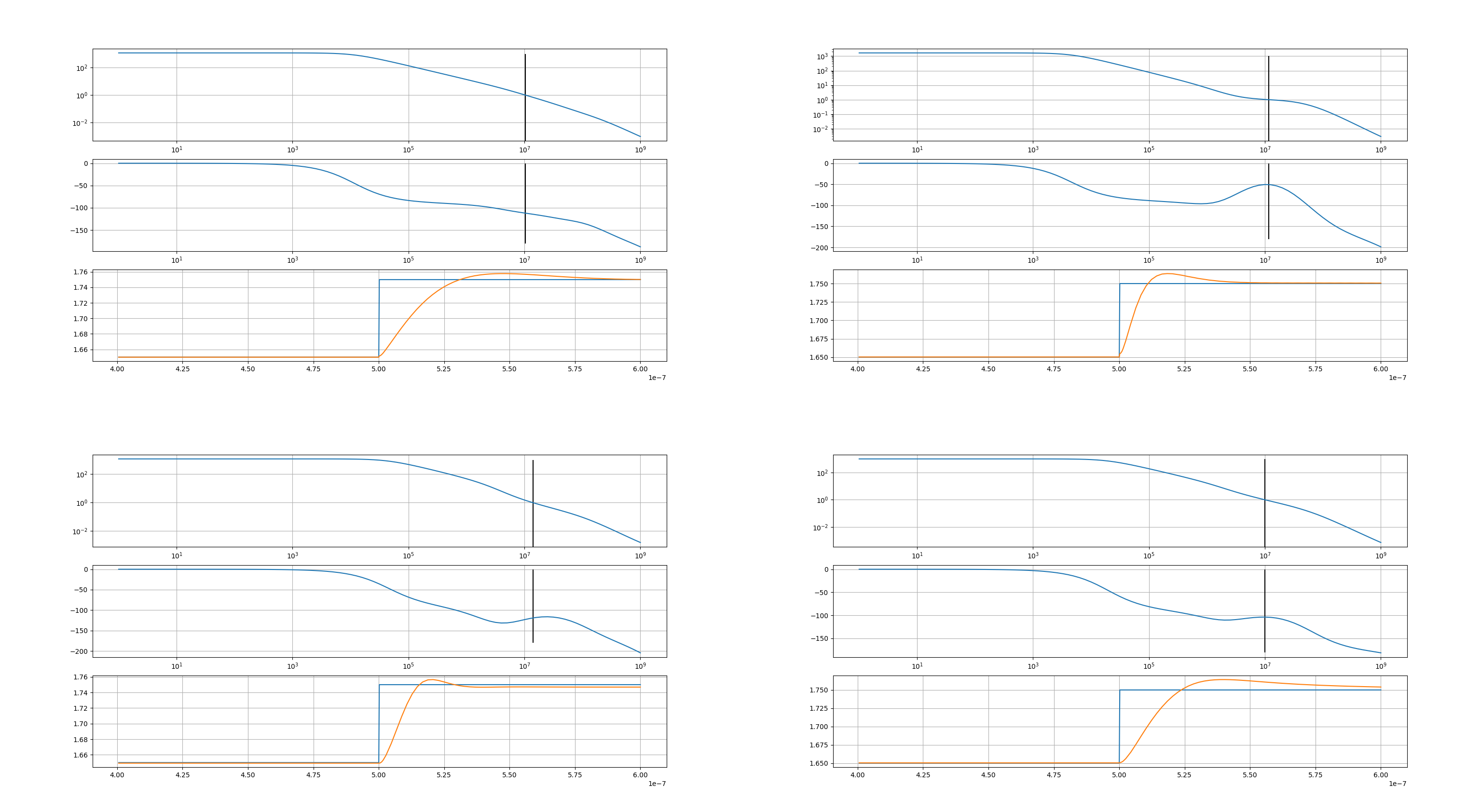
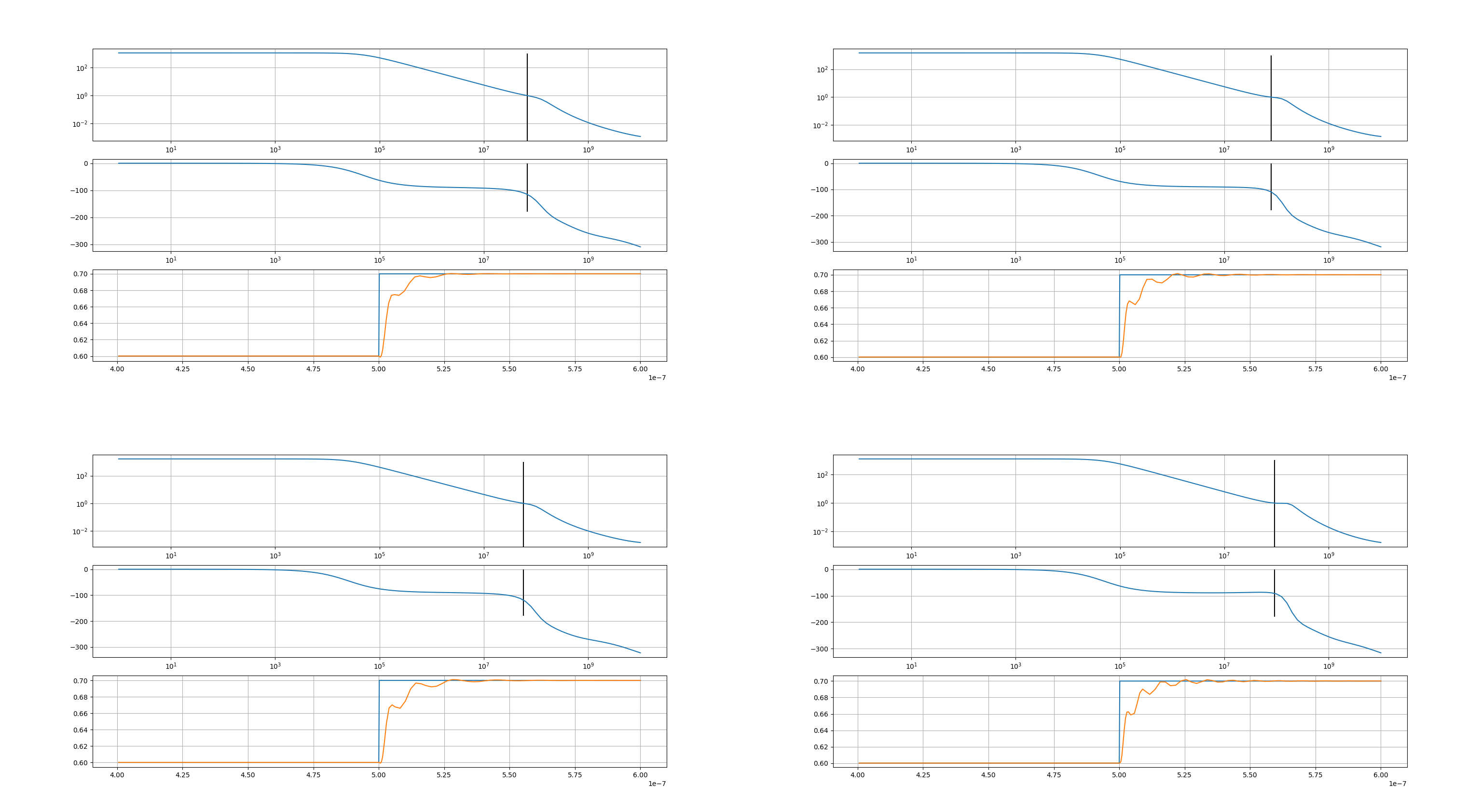
在 sizer.calculators 模块里,作者用numpy科学计算库,实现了很多从波形中提取性能指标的计算器函数,功能和Cadence Spectre里内置的计算器差不多。经过测试,这些函数性能非常好,大多数能在40 μs内返回结果。
常用的计算器函数的实现细节如下
sizer.calculators.gain()从频率响应波形中提取直流增益会先检查输入的频率响应的频率范围包不包含0 Hz,如果不包含会报错;如果包含,会返回离0 Hz最近的频率响应复数。
sizer.calculators.bandwidth()从频率响应波形中提取3 dB带宽会先使用
sizer.calculators.gain()得到直流增益,再算出直流增益的 \(1 / \sqrt{2}\) ,用一阶线性曲线给频率响应点做差值,解出直流增益 \(1 / \sqrt{2}\) 倍处的频率。sizer.calculators.phaseMargin()从频率响应波形中提取相位裕度会先用
sizer.calculators.unityGainFrequency()得到单位增益频率,然后用一阶线性曲线给横跨单位增益频率的两个频率之间的频率响应区间做插值,得到单位增益频率处的相位。sizer.calculators.unityGainFrequency()从频率响应波形中提取单位增益频率(增益降到1的时候的频率)会先检查频率响应存不存在零点,然后再用一阶线性给横跨正负轴的两个频率点之间的频率区间做插值,解出零点。
sizer.calculators.slewRate()从瞬态波形中提取切换速率一边给瞬时曲线做一阶差分,一边记录一阶差分的最大值。复杂度 \(O(n)\) ,一次扫描就能给出结果。
sizer.calculators.risingTime()从瞬态波形中提取上升时间会先寻找低阈值所在的频率点,再从这个频率点之后找高阈值所在的频率点。复杂度 \(O(n)\) ,一次扫描就能得出结果。
sizer.calculators.fallingTime()从瞬态波形中提取下降时间和
sizer.calculators.risingTime()同理。
5.4 调用仿真器
sizer使用的是开源仿真器ngspice 17 。ngspice支持三种调用模式
ngspice以一个守护进程运行
程序通过socket与它通信,向其提交仿真申请,并等待ngspice仿真完成后通过socket返回结果。
动态链接ngspice的动态链接库
这种情况下ngspice并不是以一个进程独立运行的,而是在宿主程序的内存里以代码段的形式存在。宿主程序直接把包含仿真指令的数组指针、结构体指针传给代码段里的函数。
这种模式是速度最快的,因为不涉及进程间通信,没有进程间通信开销。但是因为需要生成动态链接库,涉及编译,并且还需要手动管理内存资源分配和释放,并不是最方便的一种。
ngspice以一个命令行用户交互程序运行,程序通过子进程和进程间管道 18 通信
具体做法是先fork出一个ngspice子进程,然后把子进程的stdin和stdout和自己用pipe连接起来,自己假装成用户给ngspice发送仿真指令,ngspice完成仿真之后,会将仿真结果输出到stdout,stdout正好通过pipe与主进程连接、再把数据输出到主进程。
- 17
ngspice的主页 http://ngspice.sourceforge.net
- 18
即pipe。
作者并没有直接关心与ngspice的交互,这一切都用PySpice库实现了。PySpice可以以第二种和第三种模式调用ngspice。
5.5 优化算法的实现
sizer的优化器在模块 sizer.optimizers 中,目前有
sizer.optimizers.ScipyMinimizeOptimizer使用的是scipy实现的L-BFGS算法sizer.optimizers.ScipyDifferentialEvolutionOptimizer使用的是scipy实现的差分进化算法sizer.optimizers.ScipyDualAnnealingOptimizer使用的是scipy实现的双退火算法sizer.optimizers.ScipyBasinHoppingOptimizer使用的是scipy实现的盆地跳跃 19 算法sizer.optimizers.PyswarmParticleSwarmOptimizer使用的是pyswarm库实现的粒子群算法
大量使用scipy、pyswarm等外部库来实现优化算法、而不是自己手动用Python实现的原因是
这些库经过了大量科学计算的实践,同时是社区开源作品,因此较为成熟可靠。
scipy的底层实现是C语言,而且针对Intel CPU做了相当多的优化,比如链接了Intel MKL科学计算库,可以充分利用Intel CPU的SIMD 20 特性,利用多核并行计算来加速。